GLM-5.2 Review: Benchmarks, Cost & How It Compares to DeepSeek and MiniMax.
GLM-5.2 tops the open weights leaderboard with a score of 51 on the Intelligence Index. Here's a breakdown of its benchmarks, cost per task, and how it stacks up.
GLM-5.2 Review: Benchmarks, Cost & How It Compares to DeepSeek and MiniMax.
Z AI quietly dropped GLM-5.2 this week, and the benchmark numbers are surprisingly good — good enough that it's worth actually breaking them down rather than just skimming the headline score.
The short version: it's now the top open weights model on Artificial Analysis's Intelligence Index v4.1, sitting at 51 points. That puts it 7 points clear of both MiniMax-M3 and DeepSeek V4 Pro, which are tied at 44. Kimi K2.6 comes in at 43. GLM-5.1, the previous version, scored 40. So this isn't a minor patch — it's an 11-point jump on the same model architecture.
That last part matters. GLM-5.2 is the same size as GLM-5.1: 744B total parameters, 40B active. Z AI didn't scale its way to these results. Whatever changed happened in training.
The Benchmark Gains Are Real, Not Cherry-Picked
When a model posts a big headline number, the first thing worth checking is whether the gains are concentrated in one benchmark or spread across the board. Here, they're spread.
Scientific reasoning took the biggest jump. On CritPt, it gained 16 points, landing at 21%. On HLE — Humanity's Last Exam, one of the harder evals out there, it added 12 points to reach 40%. GPQA Diamond, another tough science benchmark, moved up 3 points to 89%. SciCode improved 7 points to 50%.
But it didn't stop there. TerminalBench v2.1 went up 16 points to 78%. AA-LCR (a coding eval) gained 9 points to hit 71%. Tau3 banking, which tests financial domain reasoning, jumped 15 points to 27%. That's a meaningful improvement across science, coding, terminal tasks, and finance — not a single-category optimisation.
On Agentic Tasks, It's Competing with Closed Models
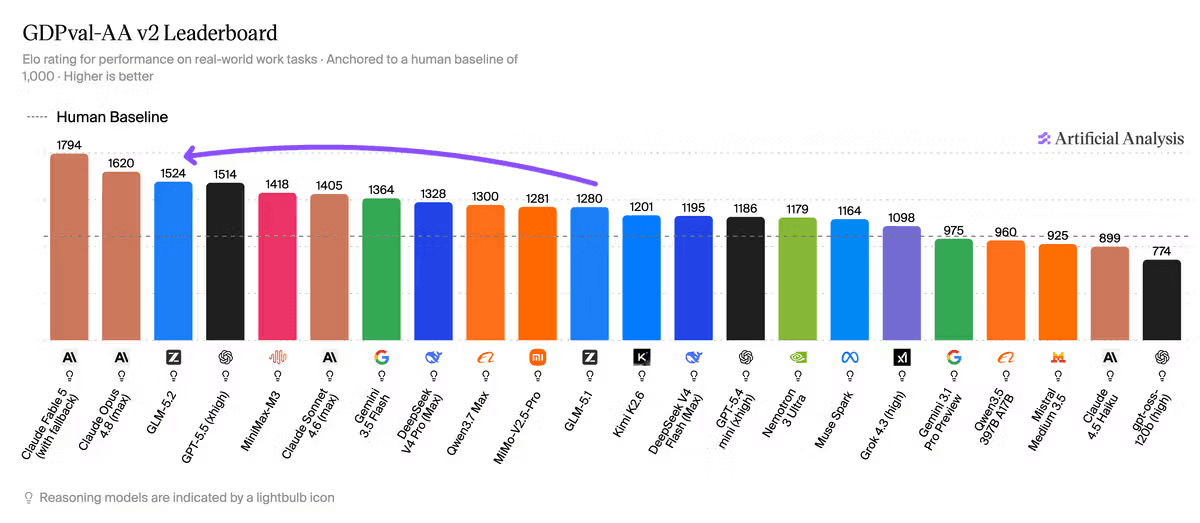
The number that stands out most in Artificial Analysis's evaluation is the GDPval-AA v2 score. This is an agentic benchmark — it tests models on real-world multi-step tasks, not one-shot question answering. It baselines Elo to human performance at 1000 and allows up to 250 turns per task, which gives long-horizon agents room to actually demonstrate capability.
GLM-5.2 scores 1524 on this eval. MiniMax-M3 is at 1418. DeepSeek V4 Pro (max) is at 1328. And GPT-5.5 at xhigh reasoning — a closed, proprietary model — scores 1514.
GLM-5.2 beat GPT-5.5 on this one. That's not something you see from an open weights model very often, and it's worth sitting with for a second. The gap between open and closed models on agentic tasks has been significant for a while. This result suggests that the gap is narrowing faster than most people expected.
Factuality Improved Too, Quietly
The AA-Omniscience Index measures how well a model handles knowledge-intensive questions — balancing accuracy against hallucination rate. GLM-5.2 scores 4 here, up from GLM-5.1's score of 2.
Under the hood: accuracy went from 24.2% to 25.1%, and the hallucination rate dropped from 29.4% to 28.1%. Attempt rate held flat at 47%. None of these is dramatic swings in isolation, but they move in the right direction together — the model is answering more questions correctly and making things up slightly less often.
The Honest Tradeoff: It's Verbose
GLM-5.2 uses 43k output tokens per Intelligence Index task, of which 37k is reasoning. That's up significantly from GLM-5.1's 26k, and it's higher than every other leading open weights model at this intelligence level — MiniMax-M3 uses 24k, Kimi K2.6 uses 35k, DeepSeek V4 Pro (max) uses 37k.
More tokens mean a higher cost per task. GLM-5.2 comes in at roughly $0.46 per task. MiniMax-M3 is $0.18, Kimi K2.6 is $0.31, and GLM-5.1 was $0.25. DeepSeek V4 Pro at max is notably cheap at $0.05, though it scores much lower on intelligence.

So GLM-5.2 earns its scores partly by reasoning longer. Whether that's a problem depends on your use case — for tasks where quality matters more than throughput, it's a reasonable tradeoff. For high-volume inference where cost-per-call is the primary constraint, MiniMax-M3 or DeepSeek V4 Pro are going to be harder to ignore.
That said, Artificial Analysis does place GLM-5.2 on the Pareto frontier of the Intelligence vs. Cost per Task chart — meaning at its intelligence level, there's no cheaper option. That's a meaningful position to hold.
Specs and Availability
The context window expanded from 200K tokens on GLM-5.1 to 1M tokens on GLM-5.2. For long-document work or extended agentic sessions, that's a real quality-of-life improvement.
Pricing on Z AI's first-party API is $1.40 per 1M input tokens, $4.40 per 1M output tokens, and $0.26 per 1M cache hit tokens — unchanged from GLM-5.1.
The model is available via Z AI's API and through a range of third-party providers: DeepInfra, Novita, Nebius, Parasail, Siliconflow, GMI Cloud, Baseten, and Fireworks. License is MIT.
Bottom Line
GLM-5.2 is a legitimately strong release. Eleven points on the Intelligence Index without changing model size, a GDPval-AA v2 score that edges out GPT-5.5, and broad improvements across reasoning, coding, and domain tasks — it's a compelling update by any measure.
The token verbosity is real and worth factoring into cost projections. But if you're evaluating open weights models for agentic or reasoning-heavy workloads right now, this is the one to test first. Nothing else in the open weights space is currently ahead of it on the benchmarks that matter for that kind of work.